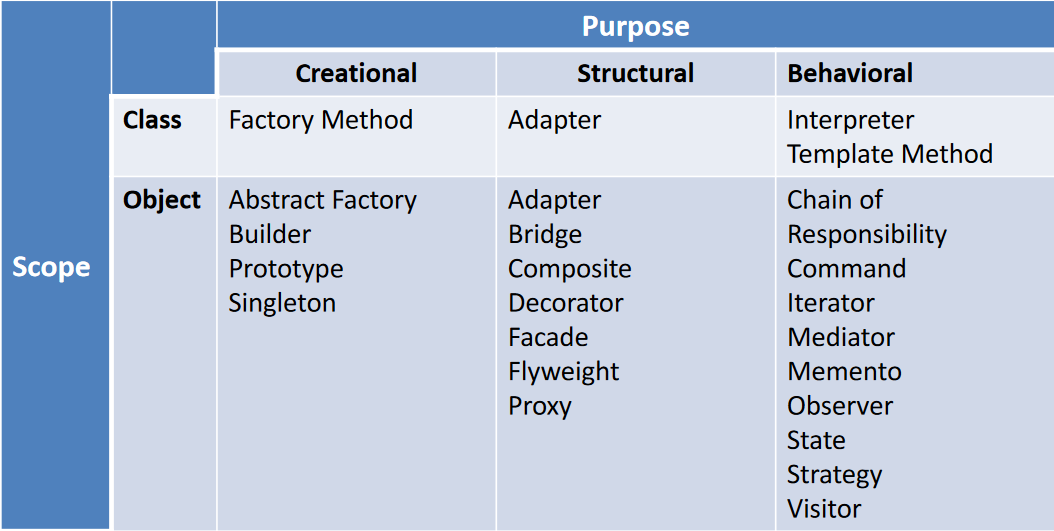
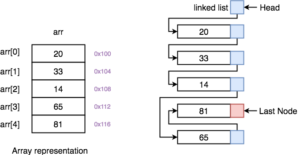
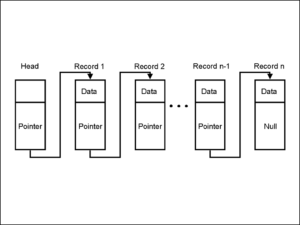
Per scrivere software di qualità anche semplici è necessario organizzarsi e non buttarsi sull’implementazione del codice. Questo permette di concentrare le risorse dove servono e ridurre al minimo le modifiche significative del codice una volta terminato il progetto.
Il primo punto fondamentale della progettazione di un software è la definizione con il cliente dei suoi requisiti. I requisiti possono essere funzionali oppure non-funzionali, e definiscono rispettivamente:
- I compiti che il programma deve svolgere (funzionali)
- Le sue caratteristiche di performance, usabilità e manutenibilità (non-funzionali)
I requisiti vengono definiti dal cliente col supporto del tecnico informatico.
Nei requisiti funzionali rientrano tutte le informazioni riguardo allo scopo del software. Partendo dal formato di Input dei dati, definendo il comportamento nei casi limite e nelle eccezioni, finendo con le modalità di salvataggio dei dati e l’interazione con l’utente.
Nei requisiti non-funzionali rientrano tutti i vincoli di
- performance richieste al software;
- il suo livello di manutenibilità (è quindi importante conoscere la vita stimata del programma e se sono previste delle modifiche);
- Che tipo di interazione con l’utente è prevista (CLI o GUI);
- Dimensioni tipiche e massime degli input;
- Piattaforme per cui il software deve essere scritto;
- Tempo a disposizione per il suo sviluppo (per definire i costi);
- Linguaggio di programmazione;
- Algoritmi utilizzati per raggiungere il risultato;
Un’altro passo fondamentale da portare avanti con la scrittura del codice è il testing. Questo deve essere eseguito durante e dopo lo sviluppo del software. L’ “Acceptance testing” è quello svolto dal cliente che determina se il software esegue o meno le operazioni richieste rientrando nei requisiti. Lo “Unit testing” invece riguarda le singole unità del software e serve allo sviluppatore per controllare ogni pezzo di codice.
Il testing può essere:
- Black-box: basato solo sui requisiti e di un software;
- White-box: progettato osservando il codice;
Definire i requisiti, e le modalità di testing permette anche di stimare correttamente il costo di un software in termini di ore di lavoro per svilupparlo; dunque definire le tempistiche in cui questo software sarà pronto.